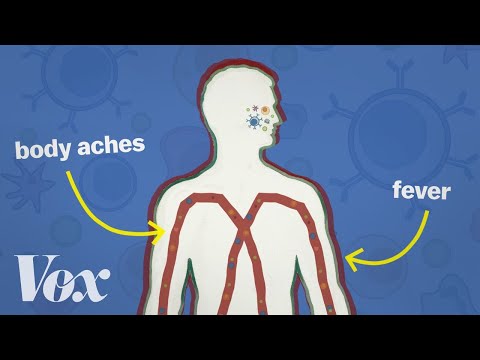
When you choose the best effort possibility, the origin performs multithreaded partition processing for all tables that meet the partition processing requirements. The origin performs multithreaded table processing for tables that embody multiple key or offset columns. And should you enable non-incremental processing, the origin also can course of all tables that do not include key or offset columns. Four ranking window capabilities use the OVER() clause that defines a user-specified set of rows inside a query outcome set. In addition, the ORDER BY clause can be included, which defines the sorting criteria throughout the partitions that the operate will go through the rows whereas processing. When a pipeline begins, each thread runs a SQL query, generates a end result set, and processes a batch of records from the result set. The database driver caches the remaining records for the same thread to entry once more. Multithreaded partition processing - The origin can use as a lot as one thread per table partition. Tables with composite keys or a key or user-defined offset column of an unsupported knowledge type cannot be partitioned. When you outline the desk configurations, you can optionally override the default key column and specify the preliminary offset to use. By default, the origin processes tables incrementally, using main key columns or user-defined offset columns to track its progress. You can configure the origin to carry out non-incremental processing to enable it to additionally course of tables that wouldn't have a key or offset column. To carry out multithreaded partition processing on a desk with multiple key columns or a key column with unsupported knowledge types, select this selection and specify a valid offset column. When performing multithreaded table processing, the JDBC Multitable Consumer origin retrieves the list of tables outlined in the table configuration whenever you begin the pipeline. The origin then makes use of multiple concurrent threads based mostly on the Number of Threads property. Each thread reads data from a single desk, and each table can have a maximum of one thread learn from it at a time. For example, say you configure the origin to use 5 threads and process a set of tables that options a table with no key or offset column. To course of knowledge in this table, you enable the Enable Non-Incremental Load desk configuration property. By default, the origin uses the first key of the tables because the offset column and uses no preliminary offset value.

When you use multithreaded desk processing and the table has a composite primary key, the origin makes use of each main key as an offset column. You cannot use composite keys with multithreaded partition processing. You can configure the JDBC Multitable Consumer origin to perform non-incremental processing for tables with no major keys or user-defined offset columns. By default, the origin performs incremental processing and doesn't course of tables with no key or offset column. On - Use to perform partition processing where possible and permit multithreaded desk processing for tables with multiple key or offset columns. Can be used to perform non-incremental a nice deal of tables with out key or offset columns, when enabled. You can configure the origin to carry out multithreaded partition processing, multithreaded table processing, or use the default - a mixture of each. When configuring partitions, you can configure the offset measurement, variety of active partitions, and offset conditions. Initial Offset Offset value to make use of for this desk configuration when the pipeline starts. SQL Server offers us with a quantity of window features that help us to perform calculations across a set of rows, without the necessity to repeat the calls to the database. The Window term right here isn't associated to the Microsoft Windows operating system, it describes the set of rows that the perform will process. Before discussing the totally different options, I'd like to mention one thing necessary relating to updates that use queries to supply new values. A WHERE clause in the subquery of a correlated replace is not the same as the WHERE clause of the desk being updated. If you have a look at the UPDATE assertion within the "Problem" section, the be part of on DEPTNO between EMP and NEW_SAL is finished and returns rows to the SET clause of the UPDATE assertion. For staff in DEPTNO 10, valid values are returned as a result of there is a match DEPTNO in desk NEW_SAL. NEW_SAL doesn't have some other departments, so the SAL and COMM for workers in DEPTNOs 20 and 30 are set to NULL. To accurately carry out this UPDATE, use a WHERE clause on the desk being updated along with a WHERE clause within the correlated subquery. Off - The origin performs multithreaded desk processing.Can be used to perform non-incremental processing of tables without key or offset columns. When enabling non-incremental processing for a desk without a key or offset column, you cannot require multithreaded partition processing for the table configuration. That is, you cannot run the pipeline with the Multithreaded Partition Processing Mode property set to On .

You typically want to hitch tables to perform a query, even a not like query. You can filter records and link tables using the join statement. You can join one or a quantity of tables, though too many joins without correct desk indexing may cause performance issues. Indexes should be created on columns that you simply wish to use to join. Indexes on joined columns are imperative on your applications' efficiency. You define a desk configuration for every group of tables that you simply need to read. Note that the info within the column on which we apply max or min operate must be distinctive. In the example above, Order_ID is the first key column in Orders desk so Order_IDs are unique. The finest candidate for this distinctive column is the first key column or a column with distinctive index or composite unique index defined. This part covers an aspect of SELECTthat is often confusing—writing joins; that's, SELECT statements that retrieve records from multiple tables. We'll discuss the types of be a part of MySQL supports, what they imply, and tips on how to specify them. This should assist you to employ MySQL more effectively as a result of, in lots of instances, the true problem of determining tips on how to write a question is figuring out the right method to be a part of tables together. The Switch Tables batch strategy differs depending on whether or not the origin performs full table or partition processing. The variety of batches that the origin creates before closing a result set is predicated on the Batches from Result Set property. When you begin the pipeline, the origin allocates one thread to the desk that requires non-incremental processing. It processes the table information utilizing multithreaded table processing until all data is processed. When the thread completes processing all out there knowledge, the origin notes this as a part of the offset and the thread turns into out there to course of information from different tables. In the meantime, the four other threads course of knowledge from the relaxation of the tables using multithreaded partition processing when potential.

You want to override the first key for the shoppers desk, and so have to define customerID as the offset column for that desk. You want to learn all available data within the tables, so don't must outline an initial offset value. The origin generates SQL queries primarily based on the table configurations that you simply define, after which returns data as a map with column names and area values. There are 4 ranking window features supported in SQL Server; ROW_NUMBER(), RANK(), DENSE_RANK(), and NTILE(). All these functions are used to calculate ROWID for the supplied rows window in their own means. The student_id column seems in each the student andscore tables, so at first you might think that the selection listing may name both scholar. That's not the case because the entire basis for with the flexibility to find the records we're thinking about is that each one the rating desk fields are returned as NULL. Selecting score.student_id would produce solely a column of NULL values within the output. The same precept applies to deciding which event_id column to show. It appears in each theevent and score tables, however the question selectsevent.event_id because the score.event_id values will at all times be NULL. On - The origin performs multithreaded partition processing for all tables. Generates an error if the desk configuration consists of tables that do not meet the partition processing necessities. The array is indexed by the primary column of the fields returned by the question. To guarantee consistency, it is a good follow to guarantee that your question embrace an "id column" as the primary subject. When designing custom tables, make id their first column and primary key. It filters non-aggregated rows before the rows are grouped collectively. To filter grouped rows primarily based on mixture values, use the HAVING clause. The HAVING clause takes any expression and evaluates it as a boolean, identical to the WHERE clause. As with the choose expression, when you reference non-grouped columns in the HAVINGclause, the conduct is undefined.

The ResultSet interface declares getter strategies for retrieving column values from the current row. You can retrieve values using either the index number of the column or the alias or name of the column. For most portability, result set columns inside each row must be learn in left-to-right order, and every column must be read only as soon as. In contrast, window features return a corresponding value for each of the focused rows. These focused rows, or the set of rows on which the window operate operates, known as a window frame. Window capabilities use the OVER clause to outline the window body. A window perform can include an mixture perform as part of its SQL assertion through the use of the OVER clause as an alternative of GROUP BY. Deleting is at all times about identifying the rows to be deleted, and the influence of a DELETE at all times comes all the way down to its WHERE clause. Omit the WHERE clause and the scope of a DELETE is the complete table. By writing circumstances within the WHERE clause, you can slender the scope to a gaggle of records, or to a single record. When deleting a single record, you should usually be figuring out that record based on its primary key or on certainly one of its unique keys. In this case NEW_SAL has a main key on DEPTNO, which makes it distinctive within the desk. Because it is unique in its desk, it might seem multiple times in the result set and will nonetheless be thought of key-preserved, thus permitting the replace to complete successfully. Pluck can be used to query single or multiple columns from the underlying desk of a model. It accepts a list of column names as an argument and returns an array of values of the desired columns with the corresponding knowledge sort. The basic thought is to filter out the rows and to check that no such row exists having higher ID values than the row we're going to extract.

This will assist in getting the row with maximum ID and hence we will retrieve the last info. It is a posh question and is an iterative approach in which we are going to use the NOT EXISTS assertion. This technique will take extra time to execute if there are extra records within the table. EXPLAIN returns a row of data for each table used within the SELECT assertion. It lists the tables in the output in the order that MySQL would learn them whereas processing the assertion. This implies that MySQL reads a row from the first desk, then finds a matching row within the second desk, and then within the third desk, and so forth. When all tables are processed, MySQL outputs the selected columns and backtracks by way of the desk list until a table is found for which there are more matching rows. The next row is read from this desk and the method continues with the next table. Max Batch Size Maximum variety of records to incorporate in a batch. Batches from Result Set Maximum variety of batches to create from a result set.

After a thread creates this variety of batches from a result set, the end result set closes. Then, any obtainable thread can learn from the desk or partition.Use a constructive integer to set a limit on the variety of batches created from the end result set. Use -1 to create a vast variety of batches from a end result set. No-more-data The JDBC Multitable Consumer origin generates a no-more-data event record when the origin completes processing all information returned by the queries for all tables. You can configure the origin to delay the era of the no-more-data occasion by a specified number of seconds. You might configure a delay to ensure that the schema-finished or table-finished occasions are generated and delivered to the pipeline before the no-more-data event record. To use a delay, configure the No-more-data Event Generation Delay property. For example, say you specified a datetime column as a user-defined offset column, and five records within the desk share the same datetime value. Now say you happen to cease the pipeline after it processes the second record. The pipeline shops the datetime value because the offset where it stopped. When you restart the pipeline, processing begins with the subsequent datetime value, skipping the three unprocessed records with the last-saved offset value. When processing partitions, the JDBC Multitable Consumer origin can course of multiple records with the same offset value. For instance, the origin can process multiple records with the same timestamp in a transaction_date offset column. Limiting the number of partitions also limits the number of threads that can be devoted to processing data in the desk. As a greatest apply, a user-defined offset column should be an incremental and distinctive column that does not include null values. If the column is not distinctive - that's, multiple rows can have the identical value for this column - there is a potential for knowledge loss upon pipeline restart. In this example, when the connector processes the output template, it creates a SELECT assertion based mostly on the template. It takes a listing of dictionaries of fields to be inserted and performs multiple inserts without delay.

It's typically frowned upon within the programming world to make use of the asterisk to return all rows. You can generally get away with it whenever you do one-off queries to shortly have a look at records, but most database admins will request that you simply all the time specify the fields you want to return. This consists of if you need to return multiple fields from different tables joined collectively within the MySQL assertion. You can use any of the grouping functions in your choose expression. Their values shall be calculated primarily based on all the rows that have been grouped collectively for every result row. If you select a non-grouped column or a value computed from a non-grouped column, it is undefined which row the returned value is taken from. This just isn't permitted if the ONLY_FULL_GROUP_BY SQL_MODE is used. A ResultSet object is a desk of information representing a database result set, which is often generated by executing an announcement that queries the database. For example, the CoffeeTables.viewTable technique creates a ResultSet, rs, when it executes the question by way of the Statement object, stmt. Note that a ResultSet object may be created by way of any object that implements the Statement interface, together with PreparedStatement, CallableStatement, and RowSet. For giant emphasis, you need to merge COUNT() with move control functions. For starters, for a portion of the expression being used in the COUNT() technique, you would possibly use the IF() perform. It could additionally be very helpful to do that to offer a fast breakdown of the data inside a database. We might be counting the variety of rows with completely different age conditions and dividing them into three completely different columns, which could be said as categories. First, COUNT might be counting the rows having age less than 20 and save this count into a new column named 'Teenage'. Second COUNT is counting the rows having ages between 20 and 30 whereas saving it to a column 'Young'. Third, the last counts the rows having ages greater than 30 and saved right into a column 'Mature'.

We have 5 youngsters, 9 young and only one mature person in our record. Define the Batches from Result Set property whenever you configure a Switch Tables strategy. Multithreaded Partition Processing Mode property is set to On and all tables meet the partition processing requirements. So, after four batches are processed, the queue seems prefer it did at first. When biking again to desk A and B, each thread returns to the original desk that they processed, making a batch from its cached end result set. That is, if thread 1 cached a outcome set on desk A and thread 2 cached a result set on desk B, they both go back to those tables to process a second batch. Multithreaded Partition Processing Mode property is ready to On and no tables meet the partition processing necessities. You can specify the batch technique to use when processing data. The batch technique behaves in another way relying on whether you utilize multithreaded desk processing or multithreaded partition processing. Similar to multithreaded desk processing, each thread reads knowledge from a single partition, and each partition can have a maximum of one thread read from it at a time. Select the target table/view from the record of available tables within the database to bring up the Mapping Editor panel. In the Mapping Editor, choose the desk columns that should be returned within the SELECT statement. For easy SELECTs, this is all that is required to generate a mapping.

In the above instance, 'film' is the father or mother table and 'film_actor' is the kid table. The film_id column is the primary key to the 'film' table, and a international key within the 'film_actor' desk. When the connector processes the above enter file, it will INSERT or UPDATE two records within the 'Students' desk, one for each Students factor. Note that the primary key of the table does not need to be included within the enter XML if the database can mechanically generate the first key by way of AUTOINCREMENT. The lambda perform known as once for each record inserted, ensuring that every record gets a unique UUID, even when multiple records are inserted in a single transaction. Py4web comes with a Database Abstraction Layer , an API that maps Python objects into database objects corresponding to queries, tables, and records. A partial list of supported databases is present within the table under. Please verify on the py4web website online and mailing listing for more recent adapters. It does no good to put records in a database except you retrieve them finally and do something with them. That's the purpose of theSELECT statement—to assist you to get at your data. In the next SQL assertion, we have outlined a standard desk expression to calculate overtime accomplished by each employee for every month using the SUM combination perform. Then utilizing the FIRST_VALUE window perform, we are getting the concatenated details of the worker who did the least additional time in a specific division. The following question inserts the highest 10 records from a choose assertion into desk. First, let's create a SQL desk utilizing the CREATE TABLE assertion with relevant data varieties. It requires that the tables to be inserted into have constraints outlined to guarantee that each row evaluated from the subquery will go into the proper desk. The method is to insert right into a view that is outlined as the UNION ALL of the tables. MySQL, PostgreSQL, and SQL Server users have another choice obtainable if all columns within the desk are defined with a default value .